I am going to rip off something Zach Weiner has been doing on his blog where he’s blogging his way through a few different textbooks. This sounds like an awesome way to get a better understanding out of stuff, so I am going to completely steal the idea from him, including the way he formats his titles (while giving him full credit as my inspiration) and blog my way through some of the textbooks I bought in university but never really actually bothered to crack open. Perhaps more fun for me than for you, but we’ll see how it goes.
 The textbook I’m going to start off with is called An Introduction to Gödel’s Theorems written by Peter Smith. From the bits of it I’ve actually made use of, it’s a fairly detailed logic text while still being relatively accessible to anyone with a bit of background. Some of the concepts it seems to take for granted are elementary set theory, introductory logic, and basic computability theory. But most everything we’ll need seems to be covered in the text.
The textbook I’m going to start off with is called An Introduction to Gödel’s Theorems written by Peter Smith. From the bits of it I’ve actually made use of, it’s a fairly detailed logic text while still being relatively accessible to anyone with a bit of background. Some of the concepts it seems to take for granted are elementary set theory, introductory logic, and basic computability theory. But most everything we’ll need seems to be covered in the text.
1 What Gödel’s Theorems say
1.1 Basic arithmetic
A lot of what is going to be covered in the text has to do with basic arithmetic, which is to say the natural numbers (0, 1, 2, etc…) and operations on them (addition, multiplication, etc…). Although this will all be flushed out formally in a few chapters, the natural numbers have a specific starting point, 0, each one has a unique successor, and every number falls into this sequence. But this will all be made formal in short order.
Our bigger concern is the notion of a formalized mathematics. In 1920 mathematician David Hilbert put forward a program to axiomatize all of mathematics into a set of finite, simple and non-controversial mathematical statements. The goal was to lift mathematics up by its bootstraps and prove the completeness and consistency of mathematics from these axioms in order to leave zero doubt as to their correctness.
The idea would be that mathematics could be axiomatized into a theory  (a theory is simply a collection of axioms) that would be (negation) complete, which is to say that for any sentence
(a theory is simply a collection of axioms) that would be (negation) complete, which is to say that for any sentence  , either or
, either or 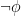 would be provable in .
would be provable in .
Thus, in our case, we are considering how one could build a complete theory of basic arithmetic where we could prove (or disprove) conclusively the truth of any claim that could be expressed arithmetically. This is where Gödel’s Theorems come into play…
1.2 Incompleteness
… by basically shitting all over the idea. What mathematician Kurt Gödel was able to do in a 1931 paper was present a way to, given a theory which was sufficiently strong enough to express arithmetic, construct a sentence  such that neither nor
such that neither nor 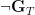 can be derived in , yet we can show that if is consistent then will be true.
can be derived in , yet we can show that if is consistent then will be true.
Thus, basic arithmetic in its most striped-down form fails to be negation complete, which puts quite a dampener on Hilbert’s program.
The specifics of how is actually constructed is the subject of most of the text, but the gist of it is this: encodes the sentence “ is unprovable in “. Thus, is true iff can’t prove it. Suppose then that is sound (ie: cannot prove a false sentence). Then if it were to prove it would prove a falsehood, which violates soundness. Thus does not prove and so is true. Thus, is false, which means that can’t prove it either. Again, how is constructed is what we’ll be getting to, but this is the gist of Gödel’s First Theorem.
It should also be noted that there isn’t only one such sentence that renders incomplete. Suppose we decide to augment by adding to it, to create a new theory  . We will then be able to construct a new Gödel sentence,
. We will then be able to construct a new Gödel sentence,  which will be true but unprovable in
which will be true but unprovable in  . Since encompasses , will also be unprovable in and we get a construction of an infinite number of unprovable-in- sentences.
. Since encompasses , will also be unprovable in and we get a construction of an infinite number of unprovable-in- sentences.
Thus, arithmetic is not only incomplete, but indeed incompletable.
1.3 More incompleteness
This incompletability does not just affect arithmetic. In fact it will also affect any systems which could be used to represent arithmetic. For example, set theory can define the empty set  . Then, form the set
. Then, form the set  containing the empty set, followed by the set containing both these sets
containing the empty set, followed by the set containing both these sets  and so on. We get a sequence of the form:
and so on. We get a sequence of the form:
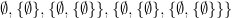
where we can define 0 as , 1 as the set containing 0, 2 as the set containing 0 and 1, and so on. The successor of  is unioned with itself (ie:
is unioned with itself (ie:  ), addition is defined as iterated succession, multiplication as iterated addition and all of a sudden you have a theory of arithmetic encompassed in set theory. By Gödel’s First Theorem, then, set theory is also incomplete.
), addition is defined as iterated succession, multiplication as iterated addition and all of a sudden you have a theory of arithmetic encompassed in set theory. By Gödel’s First Theorem, then, set theory is also incomplete.
1.4 Some implications?
This section deals with some philosophical implications of the First Theorem, but doesn’t delve into enough detail to be worth talking about.
1.5 The unprovability of consistency
Any worthwhile arithmetical theory will be able to prove the proposition  . Thus, any decent theory that proves
. Thus, any decent theory that proves 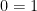 will be inconsistent. Furthermore, an inconsistent theory can prove any proposition, including , thus a theory of arithmetic is inconsistent iff proves . Now, we’ve already established that we can encode facts about the provability of propositions in , thus we have a way to encode the idea that can’t prove , which is to say that can express its own consistency. We’ll call the sentence that expresses this
will be inconsistent. Furthermore, an inconsistent theory can prove any proposition, including , thus a theory of arithmetic is inconsistent iff proves . Now, we’ve already established that we can encode facts about the provability of propositions in , thus we have a way to encode the idea that can’t prove , which is to say that can express its own consistency. We’ll call the sentence that expresses this 
From above, we’ve already seen that a consistent theory can’t prove . Since is itself the sentence that expresses its own unprovability, we can then express (in ) that if is consistent then is unprovable by  .
.
Make sense?
According to the text, it turns out (although we’ve yet to see how) that this sentence turns out to be provable within theories with conditions only slightly stronger than those required for the First Theorem. However must still be unprovable within such theories, and so must also be unprovable otherwise we would be able to get by simple modus ponens.
As such, we have Gödel’s Second Incompleteness Theorem: that nice theories that can express a sufficient amount of arithmetic can’t prove their own consistency.
1.6 More implications?
The key point that I took from this section is that since we’ve shown that a theory of arithmetic can’t prove its own completeness or consistency, then it certainly can’t prove the same for a richer theory 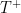 . This rudely defeats what remains of Hilbert’s Programme, as arithmetic isn’t capable of validating itself, let alone the rest of mathematics.
. This rudely defeats what remains of Hilbert’s Programme, as arithmetic isn’t capable of validating itself, let alone the rest of mathematics.
1.7 What’s next?
Obviously this is all pretty roughshod. In chapter 2 we go over a few basic notions that we will need to prove things in more detail. Chapter 3 discusses what is meant by an “axiomatized theory”. Chapter 4 introduces concepts specific to axiomatized theories of arithmetic. Chapters 5 and 6 give us some more direction as we head off towards formally proving… pause for dramatic music… Gödel’s First Incompleteness Theorem!

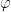




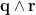


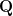
 but that sentence is meaningless unless I also inform you that
but that sentence is meaningless unless I also inform you that  means “
means “ knows
knows  “,
“, 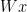 means “
means “ means “
means “ mean “John” and “Amy” respectively.
mean “John” and “Amy” respectively. as being a pair
as being a pair  where
where  is a syntactically defined system of expressions and
is a syntactically defined system of expressions and  is an intended interpretation of those expressions.
is an intended interpretation of those expressions.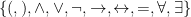 . Our non-logical vocabulary is a bit more complicated in that it needs to potentially address infinitely many variables. There are two ways to do this. The way I like to think of it is having
. Our non-logical vocabulary is a bit more complicated in that it needs to potentially address infinitely many variables. There are two ways to do this. The way I like to think of it is having  which gives you an infinite set containing all of your variables
which gives you an infinite set containing all of your variables 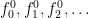 , all of your
, all of your  -place predicates
-place predicates  and all of your
and all of your  -place functions
-place functions 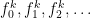 . But, of course, this results in an infinite alphabet of symbols. The book chooses to accomplish this by having your variables be something like
. But, of course, this results in an infinite alphabet of symbols. The book chooses to accomplish this by having your variables be something like  which operates on a finite alphabet (
which operates on a finite alphabet ( ). In either case, we will typically just denote variables as
). In either case, we will typically just denote variables as 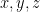 , predicates as
, predicates as  , functions as
, functions as 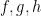 and so on. As stated in the previous section, we don’t always need to use perfect rigour but it’s important to understand how it would be accomplished. The union of the logical and non-logical vocabularies form the language’s alphabet. To see how first-order logic determines its wffs, see
and so on. As stated in the previous section, we don’t always need to use perfect rigour but it’s important to understand how it would be accomplished. The union of the logical and non-logical vocabularies form the language’s alphabet. To see how first-order logic determines its wffs, see  to Socrates and Plato respectively, and the meaning of the predicate
to Socrates and Plato respectively, and the meaning of the predicate 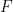 to mean “is wise”. Then
to mean “is wise”. Then  and
and  is true iff
is true iff  is true and
is true and  is true. This can be tedious but straightforward. Again, however, it is important that this process be an effectively decidable one.
is true. This can be tedious but straightforward. Again, however, it is important that this process be an effectively decidable one. (where
(where 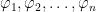 to a conclusion
to a conclusion 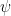 is valid. Note that this is different from having an effective procedure to actually create this derivation. All is has to do is determine whether a given proof which has been provided is valid for teh system.
is valid. Note that this is different from having an effective procedure to actually create this derivation. All is has to do is determine whether a given proof which has been provided is valid for teh system.
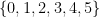 . But what does it mean to effectively enumerate an infinite set? Consider the program:
. But what does it mean to effectively enumerate an infinite set? Consider the program:
 , but can we formalize the notion of a non-terminating program being used to enumerate an infinite set? This isn’t discussed in the book, but I like to think of it as follows:
, but can we formalize the notion of a non-terminating program being used to enumerate an infinite set? This isn’t discussed in the book, but I like to think of it as follows: is said to list an element
is said to list an element  iff there, after some finite number of steps of execution
iff there, after some finite number of steps of execution  will be listed after exactly
will be listed after exactly 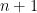 steps (if we ignore steps involved in managing the loop logic.
steps (if we ignore steps involved in managing the loop logic. . This set is then enumerable by the program:
. This set is then enumerable by the program:
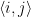 is effectively enumerable.
is effectively enumerable.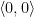
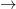





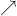

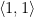
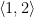
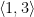

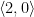

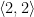
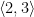

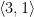




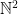 .
.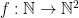 that will do this without the use of the table, however it doesn’t go into details and even if it did, this exercise can be quite messy. The way I actually know how to do it doesn’t involve the table at all and actually goes the other way,
that will do this without the use of the table, however it doesn’t go into details and even if it did, this exercise can be quite messy. The way I actually know how to do it doesn’t involve the table at all and actually goes the other way,  . It looks like:
. It looks like:
 such that
such that  , but this is complex and involves
, but this is complex and involves  -calculus which I’m not ready to get into yet.
-calculus which I’m not ready to get into yet. is enumerable if its members can – at least in principle – be listed off in some order (a zero-th, first, second) with every member appearing on the list; repetitions are allowed, and the list may be infinite.
is enumerable if its members can – at least in principle – be listed off in some order (a zero-th, first, second) with every member appearing on the list; repetitions are allowed, and the list may be infinite.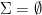 (where
(where  is an enumeration of the finite set
is an enumeration of the finite set  also enumerates
also enumerates 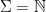 (where
(where 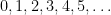


 position. In 2.
position. In 2.  entries down if
entries down if 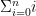 entries into the list. Note that to make the math easier, we start our counting at zero: thus, the left-most element listed is the “zero-th”, the next is the first, the next is the second and so on. Now 2. and 3. are contrived examples but the point they make is that each
entries into the list. Note that to make the math easier, we start our counting at zero: thus, the left-most element listed is the “zero-th”, the next is the first, the next is the second and so on. Now 2. and 3. are contrived examples but the point they make is that each 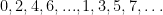


 (so that
(so that  ). We say that such a function enumerates
). We say that such a function enumerates  of infinite binary strings (ie: the set containing strings like
of infinite binary strings (ie: the set containing strings like  ). Obviously
). Obviously  does exist. Then, for example,
does exist. Then, for example, 
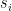 aren’t important (as we will see) so this example will abstract to the general case. What we are going to do now is construct a new string,
aren’t important (as we will see) so this example will abstract to the general case. What we are going to do now is construct a new string,  , such that
, such that 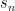 and swap it. Thus, given our example enumeration above, the first 5 characters of
and swap it. Thus, given our example enumeration above, the first 5 characters of  which we get by just this method (for convenience, the
which we get by just this method (for convenience, the 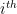 position. As such,
position. As such,  can be thought of as representing a real binary decimal number
can be thought of as representing a real binary decimal number  (ie:
(ie:  would represent
would represent  and
and  would represent
would represent  . Thus we know that the real numbers in the interval
. Thus we know that the real numbers in the interval ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) are not enumerable (and so neither is the set of all real numbers
are not enumerable (and so neither is the set of all real numbers 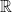 ).
). to be the set
to be the set  , where a number
, where a number  iff
iff  and
and 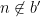 iff
iff 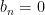 . So for example, if
. So for example, if  then
then  . Thus, the set of sets of natural numbers (denoted
. Thus, the set of sets of natural numbers (denoted  ) is also not enumerable.
) is also not enumerable. which takes a numerical property
which takes a numerical property  and maps
and maps 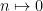 if
if  holds and
holds and  if
if  holds. (This may seem backwards, since
holds. (This may seem backwards, since  and
and  denotes
denotes  , however we will see the reasons for this in due course.) If we consider an element
, however we will see the reasons for this in due course.) If we consider an element 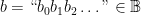 to describe a characteristic function
to describe a characteristic function  by
by  , then we can observe that the set of all characteristic functions is similarly non-enumerable.
, then we can observe that the set of all characteristic functions is similarly non-enumerable.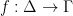 is a rule
is a rule 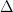 and turns it into something from its co-domain
and turns it into something from its co-domain  . We will be dealing exclusively with total functions, which means that
. We will be dealing exclusively with total functions, which means that  . In other words, the range is the set of all possible outputs of
. In other words, the range is the set of all possible outputs of  there is some
there is some  such that
such that 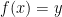 . Equivalently,
. Equivalently,  implies that
implies that  . This property is also called one-to-one because it matches everything with exactly one corresponding value.
. This property is also called one-to-one because it matches everything with exactly one corresponding value. you would probably say no. In either case you have just decided that predicate.
you would probably say no. In either case you have just decided that predicate.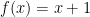 and the argument
and the argument 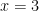 you would compute the value
you would compute the value  . If I give you the function
. If I give you the function  to the argument of the same computer program as above, you would conclude that the result is infinite. In both cases you have just computed that function.
to the argument of the same computer program as above, you would conclude that the result is infinite. In both cases you have just computed that function. -calculus,
-calculus, 
