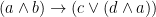(This is going to be a long one, but bear with me. Once we make it through this, I get to start talking about the cool stuff.)
4.1. Quantification
If you’ve been doing the questions for Parts II and III you may have run into some interesting quirks with symbolizing one of the arguments from Part I. Specifically:
- P1) All men are mortal.
- P2) Socrates is a man.
- C) Socrates is mortal.
Now, with a little bit of reflection, it’s clear that this argument ought to be valid. However, if we try to symbolize it using what you’ve already learned, we end up with something like:
Which, it’s pretty clear, is not going to be a valid argument. The reason it doesn’t end up working out is because the basic logical language we’ve learned (known as Sentential or Propositional Logic) has no way of formalizing the concept of “all”.
That’s why there’s a second logical language that we’ll be talking about called First-Order Logic (or Predicate Logic). It is a strict extension of Propositional Logic, which is to say that everything you’ve already learned will still apply. (Well… you won’t be doing truth tables any more, but you won’t really miss them, I promise). In our extension we introduce two new concepts to our language: “some” and “all”. Because these describe quantities, they are called “quantifiers”.
4.1.1. Predicates
Before we learn about quantifiers, however, we need to discuss something called predicates. While they do have a fancy formal definition, I’d like to leave that for a future discussion and just cover them in an intuitive sense.
A predicate is like an adjective, in that it describes something about a subject. For example, in the sentence “a baseball is round”, the predicate “is round” describes a particular subject (in this case “a baseball”). Because we have separated the two things out, we can then go on to apply the predicate to other round things: “the Earth is round”, “circles are round” and “soccer balls are round” will, instead of each being their own sentence, be represented as a single predicate applied to three different round subjects.
Symbolically, we tend to denote predicates by uppercase letters, and subjects as lowercase letters. So in the examples above, we could let  represent “is round” and then our four sentences become
represent “is round” and then our four sentences become  and
and  (where
(where  represent “baseball”, “Earth”, “circles” and “soccer balls” respectively).
represent “baseball”, “Earth”, “circles” and “soccer balls” respectively).
Typically however, we reserve letters from the beginning of the alphabet (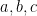 ,etc…) when we talk about particular subjects (called constants), and letters from the end of the alphabet (
,etc…) when we talk about particular subjects (called constants), and letters from the end of the alphabet (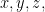 ,etc…) when we talk about generic subjects (called variables).
,etc…) when we talk about generic subjects (called variables).
4.1.2. Universal Quantification
So now that we have predicates, we can apply our first quantifier to it: the universal quantifier: 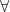 . This symbol indicates that every subject has a particular property. In order to use it in a sentence, we must bind it to a variable such as
. This symbol indicates that every subject has a particular property. In order to use it in a sentence, we must bind it to a variable such as  . Once we’ve done this, we can create our sentence:
. Once we’ve done this, we can create our sentence: 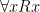 or “everything is round”.
or “everything is round”.
Now, this isn’t particularly helpful, since any useful predicate will be true of some things and not of others. That’s why we’re able to quantify over not just predicates, but other sentences. So, a more useful sentence might be 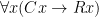 which could be read as “anything which is a circle is also round”. In fact, we can even place a quantifier in front of a quantified sentence to end up with something like
which could be read as “anything which is a circle is also round”. In fact, we can even place a quantifier in front of a quantified sentence to end up with something like  (which is a redundant sentence, but one that makes my point). Typically, we will abbreviate
(which is a redundant sentence, but one that makes my point). Typically, we will abbreviate  as
as  .
.
In fact, this is the general form that most universal quantifications will take. For all if has some sort of property then has some other sort of property. To give another example, to say “all men are mortal” we would translate that as “all things that are men are mortal” or  .
.
4.1.3. Existential Quantification
The other type of quantifier we can apply to a sentence is called an existential quantifier and is used to denote that some (or at least one) subject has a particular property. The symbol to denote this is 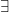 and is used in a sentence exactly the same way as a universal quantifier:
and is used in a sentence exactly the same way as a universal quantifier: 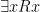 (read as “something is round”).
(read as “something is round”).
Again, this might not seem entirely useful, because it tells us nothing about what sorts of things the predicate applies to (in this case, what sorts of things are round?). But we can do another trick with them to narrow what we’re looking at by using conjunction. Take the predicate 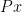 to mean “ is a plate$ then we have
to mean “ is a plate$ then we have  or “some plates are round”.
or “some plates are round”.
4.1.4. Relations
Relations are similar to predicates, except that they use more than one variable. For example, if you wish to say “James is the father of Harry”, we could take the predicate 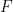 to describe a relationship between James (
to describe a relationship between James ( ) and Harry (
) and Harry ( ). Symbolically we would write this as
). Symbolically we would write this as  .
.
We aren’t just limited to two-place relations either. The predicate 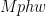 could represent the sentence “the priest married the husband and wife”. Examples with bigger and bigger relations do become more and more contrived, but technically speaking, there’s nothing to stop us.
could represent the sentence “the priest married the husband and wife”. Examples with bigger and bigger relations do become more and more contrived, but technically speaking, there’s nothing to stop us.
We can also quantify over just part of a sentence. For example  would say “someone is Harry’s father” and
would say “someone is Harry’s father” and 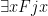 would say “James is the father of someone”.
would say “James is the father of someone”.
Additionally, for two-place relations, they are sometimes represented with something called “infix notation”. Here, instead of saying  we would write
we would write  for whatever relation we’re dealing with. I prefer not to use this notation as it doesn’t work for relations with three or more subjects. With one notable exception:
for whatever relation we’re dealing with. I prefer not to use this notation as it doesn’t work for relations with three or more subjects. With one notable exception:
4.1.4.1. Identity
We have the option of adding a special relation to our language, called identity ( ). It is a two-place relation written with infix notation that indicates that two things are the same. If we know that these two things are the same, then we can substitute one for the other in sentences. So the following sentence is valid (ie: always true) for any predicate
). It is a two-place relation written with infix notation that indicates that two things are the same. If we know that these two things are the same, then we can substitute one for the other in sentences. So the following sentence is valid (ie: always true) for any predicate  :
:

Or, stated plainly, if two things are the same then any property that holds for one will also hold for the other.
I prefer to deal with first-order logic that makes use of identity, and so that is what I shall do. You may ask why we would choose not to do so, and the answer to that is basically just that it can make proving things about first-order logic a bit trickier. But that’s outside of the scope we’re dealing with here today.
Identity also has the following properties:
- Reflexivity:

- Symmetry:
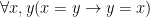
- Transitivity:

Reflexivity tells us that everything is equal to itself. Symmetry tells us that it doesn’t matter which way we order our terms. Transitivity tells us that if one thing is equal to another, and the second thing is equal to some third, then the first and third things are also equal. These are the three properties that give us something called an equivalence relation, but we’ll get to what that is when we talk about set theory.
4.2. Socrates
With all of that under our belts, let’s look back at the original question. The argument:
- P1) All men are mortal.
- P2) Socrates is a man.
- C) Socrates is mortal.
Can now easily be symbolized as:
Easy enough, right? However this still doesn’t give us a way to tell whether the argument is valid. We can’t use a truth table, because there’s simply no way to express quantification in a truth table. (Well technically we could, but only if we had a finite domain and even then it’s a pain in the ass…)
So we are still in need of a way to tell whether arguments in first-order logic are valid. Which brings us to…
4.2. Fitch-Style Calculus
There are a number of different ways to determine validity in first-order logic. I’m going to be talking about one called Fitch-Style Calculus, but there are many more including Natural Deduction (which I won’t be talking about) and Sequent Calculus and Semantic Tableaux (which I probably will).
I personally like Fitch because I find it very intuitive. A basic Fitch proof involves taking your premises and deriving a conclusion. We no longer deal with truth values, but instead we consider all of our assumptions to be true, but in a particular context. Just as an argument has two parts: premises and conclusions; so do Fitch proofs. These two parts are delimited by a giant version of the 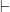 symbol. Premises (or assumptions) go on top of the symbol and conclusions go underneath. Additionally, each new line in your derivation must also be justified by a rule, which we’ll get to.
symbol. Premises (or assumptions) go on top of the symbol and conclusions go underneath. Additionally, each new line in your derivation must also be justified by a rule, which we’ll get to.
The most important concept in such derivations is that of the sub-proof. Basically a sub-proof is a brief argument-within-an-argument with its own assumptions which can be used within the sub-proof, but not in the outside proof as a whole. We will also make use of the term “scope” which basically refers to how many sub-proofs deep we are in a current argument. The rules (mentioned above) include ways to move sentences between different scopes.
I know this all sounds confusing, but we’re going to look at these rules and see whether they make sense. Before we do, I want to show you an example of a (admittedly complicated) proof, so that you can see what it looks like. You can check it out here. Take particular notice of the sub-proofs (and the sub-proofs within sub-proofs) to get an idea of how this sort of thing gets laid out. Also notice that each line is justified either as an assumption (appearing above the horizontal line of the symbol and abbreviated “Ass.” (try not to laugh)) or justified by a rule and the lines which the rule is making use of. Finally, notice that the last line is outside of any scope lines. We’ll see what this means later on.
But onto the rules! Once again, there are two different kinds: rules of inference and rewriting rules.
4.2.1. Fitch-Style Rules of Inference
Rules of inference are used to either introduce or eliminate a connective or quantifier from a sentence, or move sentences between scopes. They may require one or several lines earlier in the proof in order to make use of them. In the examples below, the line with the rule’s name next to it represents an application of that rule. Additionally, for these rules we will be using Greek letters to represent sentences which may not necessarily be atomic. This is because these rules are general forms which can be applied to very complex sentences. Thus, the symbol 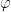 may stand for
may stand for  ,
, 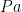 ,
, 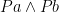 or even something as complicated as
or even something as complicated as  .
.
Each logical symbol in our language will have both an introduction rule (how to get that symbol to appear in a sentence) and an elimination rule (how to get it out). Thus, we have two rules each for  plus one more, for a total of 19 rules.
plus one more, for a total of 19 rules.
4.2.1.1 Reiteration
The first rule of inference is kind of a silly one. Quite frankly, it almost always gets left out of written proofs (in fact, it’s been left out of my example proof above). Basically it states that any line of a proof can be repeated (reiterated) at any line within the same scope or deeper. In a proof, it looks something like:
 Where basically you have some sentence and later on in the proof you repeat it. Notice that we are justifying the second appearance of it with the name of the rule: “Reit.” This is important to do in every line of your proof. Normally (as seen in my example proof) we also need to justify what lines the rule is being derived from. Because we have no line numbers here, they are omitted. There is a second (more useful, but still generally omitted) version of this rule which allows you to move a sentence into a sub-proof:
Where basically you have some sentence and later on in the proof you repeat it. Notice that we are justifying the second appearance of it with the name of the rule: “Reit.” This is important to do in every line of your proof. Normally (as seen in my example proof) we also need to justify what lines the rule is being derived from. Because we have no line numbers here, they are omitted. There is a second (more useful, but still generally omitted) version of this rule which allows you to move a sentence into a sub-proof:
 Notice however that although we can move sentences deeper into sub-proofs, we can’t take a sentence in a sub-proof and move it back outside of the sub-proof. In order to get things out of sub-proofs, we need different rules, which we’ll see shortly.
Notice however that although we can move sentences deeper into sub-proofs, we can’t take a sentence in a sub-proof and move it back outside of the sub-proof. In order to get things out of sub-proofs, we need different rules, which we’ll see shortly.
4.2.1.2. Conjunction Introduction and Elimination
These two rules are fairly straightforward. First, and-introduction:
 This rule tells us that if we have two sentences, then we can simply “and” them together. Think of it this way: since we have and we have
This rule tells us that if we have two sentences, then we can simply “and” them together. Think of it this way: since we have and we have 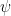 then we clearly have
then we clearly have  too.
too.
And-elimination is simply the same thing, backwards:

If we have a conjunction, then we can derive either of the two terms. Put another way, if we have then we clearly must have and also .
4.2.1.3. Implication-Introduction and Elimination
Implication-introduction is the first time we will see the use of a sub-proof in one of our rules. It has the form:
 This deserves a bit of explanation, but is pretty easy to understand once you see what’s going on. In our sub-proof, we are assuming . Now, it doesn’t actually matter whether is true or not, but for the sake of argument we are assuming that it is. Once we’ve done so, if we can somehow further derive then we are able to end the sub-proof (also called discharging our assumption) then we can conclude
This deserves a bit of explanation, but is pretty easy to understand once you see what’s going on. In our sub-proof, we are assuming . Now, it doesn’t actually matter whether is true or not, but for the sake of argument we are assuming that it is. Once we’ve done so, if we can somehow further derive then we are able to end the sub-proof (also called discharging our assumption) then we can conclude 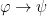 , which is just the formal way of saying “if then $psi$”, or “if we assume then we can conclude $\psi$”.
, which is just the formal way of saying “if then $psi$”, or “if we assume then we can conclude $\psi$”.
Implication elimination is identical to the Modus Ponens rule we learned in Part III. In fact, in many proofs (including my example proof above) we abbreviate the rule “MP” instead of “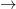 E”. To remind you, this rule has the following form:
E”. To remind you, this rule has the following form:
 As you can see, this is completely identical to what you learned about Modus Ponens earlier.
As you can see, this is completely identical to what you learned about Modus Ponens earlier.
4.2.1.4. Disjunction Introduction and Elimination
Or-introduction is also fairly straightforward and takes the form:
 Which is to say, if we have then we can loosen this to
Which is to say, if we have then we can loosen this to  for any arbitrary sentence
for any arbitrary sentence 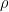 . Since disjunctions are also commutative (remember from Part III), we can also infer
. Since disjunctions are also commutative (remember from Part III), we can also infer 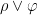 .
.
Or-elimination, on the other hand, is considerably more complex:

All this says, though is that if you have a disjunction and can derive the same sentence () from either disjunct, then regardless of whichever between or is true, must also hold. It is also important to notice that we are using two different sub-proofs. The sub-proof where we assume is completely separated from the one where we assume  . So, for example, we couldn’t use the reiteration rule to bring into the second sub-proof because this would involve reiterating it to a less deep scope level. It can be a bit of a tricky one to wrap your head around, but once you’ve played around with it a bit, it begins to make sense.
. So, for example, we couldn’t use the reiteration rule to bring into the second sub-proof because this would involve reiterating it to a less deep scope level. It can be a bit of a tricky one to wrap your head around, but once you’ve played around with it a bit, it begins to make sense.
4.2.1.5. Negation Introduction and Elimination
Negation introduction and elimination have exactly the same form. The only difference between the two is the location of the  symbol:
symbol:
In fact, we technically don’t even need both of these rules. Instead we could forgo the elimination rule and simply use the double negation rule (see below). We would do this by assuming  , deriving
, deriving 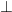 , concluding
, concluding  using I and then rewriting it to using the double negation rule. If you understand what I just said, you’re doing great so far!
using I and then rewriting it to using the double negation rule. If you understand what I just said, you’re doing great so far!
4.2.1.6. Biconditional Introduction and Elimination
These two rules basically just formalize the notion that a biconditional is literally a conditional that goes both ways. Its introduction rule has the form:
 Where, if two sentences imply each other, then they mutually imply each other. The elimination rule has the form:
Where, if two sentences imply each other, then they mutually imply each other. The elimination rule has the form:
 Where, if two things mutually imply each other, then they each imply the other on their own.
Where, if two things mutually imply each other, then they each imply the other on their own.
4.2.1.7. Bottom Introduction and Elimination
Recall that the symbol is a logical constant which represents a sentence which is always false. Basically, its only use is to enable the negation introduction and elimination rules. You might wonder how we could possibly derive a sentence which is always false when we’re assuming that our sentences are always true. Well that’s kind of the point. Observe:
 The only way to actually derive is to derive a contradiction. This will usually only happen in the context of some sub-proof which allows us to use the negation introduction and elimination rules that say basically “if your assumption leads to a contradiction, then your assumption is incorrect”. This is also a form of argument which is known as “reductio ad absurdum” where you grant an opponent’s premise to show that it is logically inconsistent with some other point.
The only way to actually derive is to derive a contradiction. This will usually only happen in the context of some sub-proof which allows us to use the negation introduction and elimination rules that say basically “if your assumption leads to a contradiction, then your assumption is incorrect”. This is also a form of argument which is known as “reductio ad absurdum” where you grant an opponent’s premise to show that it is logically inconsistent with some other point.
The bottom elimination rule does exist, but is seldom used. It has the form:
 All this does is return us to the notion that anything is derivable from a contradiction. Regardless of what actually is, if we already have a contradiction, we can infer it. It’s not like we can make it more inconsistent!
All this does is return us to the notion that anything is derivable from a contradiction. Regardless of what actually is, if we already have a contradiction, we can infer it. It’s not like we can make it more inconsistent!
4.2.1.8. Substitutions
Once we start involving quantifiers in our sentences, our rules start getting a bit muckier, because we have to deal not only with sentences containing predicates, but also terms. Because of this, we need to have something called a substitution, which I’ll explain briefly.
As the name suggests, a substitution takes one term out of a sentence and replaces it with a completely different term. This is written as ![\varphi[a/b]](https://s0.wp.com/latex.php?latex=%5Cvarphi%5Ba%2Fb%5D&bg=ffffff&fg=000000&s=0&c=20201002) where is some arbitrary sentence,
where is some arbitrary sentence,  is the term we are replacing, and
is the term we are replacing, and  is what we are replacing it with. Here are some examples:
is what we are replacing it with. Here are some examples:
![Pa[b/a]](https://s0.wp.com/latex.php?latex=Pa%5Bb%2Fa%5D&bg=ffffff&fg=000000&s=0&c=20201002) evaluates to
evaluates to 
![(Pa\wedge Qa)[b/a]](https://s0.wp.com/latex.php?latex=%28Pa%5Cwedge+Qa%29%5Bb%2Fa%5D&bg=ffffff&fg=000000&s=0&c=20201002) evaluates to
evaluates to 
![Pa[b/a]\wedge Qa](https://s0.wp.com/latex.php?latex=Pa%5Bb%2Fa%5D%5Cwedge+Qa&bg=ffffff&fg=000000&s=0&c=20201002) evaluates to
evaluates to 
![(Pa\wedge Qb)[b/a]](https://s0.wp.com/latex.php?latex=%28Pa%5Cwedge+Qb%29%5Bb%2Fa%5D&bg=ffffff&fg=000000&s=0&c=20201002) evaluates to
evaluates to ![\forall x (Px\rightarrow Rxa)[b/a]](https://s0.wp.com/latex.php?latex=%5Cforall+x+%28Px%5Crightarrow+Rxa%29%5Bb%2Fa%5D&bg=ffffff&fg=000000&s=0&c=20201002) evaluates to
evaluates to 
We may sometimes wish to talk about what terms appear in a sentence. I will use the notation  to mean that the term appears in the sentence and the notation
to mean that the term appears in the sentence and the notation  to mean that it does not. With that in mind, let’s move on.
to mean that it does not. With that in mind, let’s move on.
4.2.1.9. Existential Introduction and Elimination
Existential introduction is a way to weaken a particular statement. It takes the form:
 At any given time, we can take a concrete statement and make it abstract. To give a particular example, if we had the claim “the Earth is round” we could weaken it to say “something is round”. Which, while less helpful, is still true. We must, however, take care that the variable we are attaching to our quantifier does not already appear in our sentence. For example, if one had the sentence
At any given time, we can take a concrete statement and make it abstract. To give a particular example, if we had the claim “the Earth is round” we could weaken it to say “something is round”. Which, while less helpful, is still true. We must, however, take care that the variable we are attaching to our quantifier does not already appear in our sentence. For example, if one had the sentence  , we could derive
, we could derive 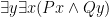 but not
but not 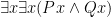 , because already appears in our formula.
, because already appears in our formula.
Existential elimination is a bit more straightforward, but also has a bit more bookkeeping involved with it:
 If we know that there is some for which is true, then we can give it a concrete name. The only thing we have to be careful about is what name we give it. In general, we can’t give it a name that is already assigned to an item. So if we had
If we know that there is some for which is true, then we can give it a concrete name. The only thing we have to be careful about is what name we give it. In general, we can’t give it a name that is already assigned to an item. So if we had 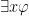 and
and  then we could derive
then we could derive ![\varphi[a/x]](https://s0.wp.com/latex.php?latex=%5Cvarphi%5Ba%2Fx%5D&bg=ffffff&fg=000000&s=0&c=20201002) . Once we’ve done so, however, we can no longer derive
. Once we’ve done so, however, we can no longer derive ![\psi[a/x]](https://s0.wp.com/latex.php?latex=%5Cpsi%5Ba%2Fx%5D&bg=ffffff&fg=000000&s=0&c=20201002) but we can derive
but we can derive ![\psi[b/x]](https://s0.wp.com/latex.php?latex=%5Cpsi%5Bb%2Fx%5D&bg=ffffff&fg=000000&s=0&c=20201002) (assuming has not already been used somewhere else within the same scope). A constant term that has not yet been used is called “fresh”.
(assuming has not already been used somewhere else within the same scope). A constant term that has not yet been used is called “fresh”.
4.2.1.10. Universal Introduction and Elimination
Universal introduction is weird, to the point where I don’t like to use it because it’s confusing. In the example proof I linked to above, I actually avoid using it and instead use a combination of negation elimination and a version of DeMorgan’s laws (see below). But for the sake of completeness, here it is:
 Once again, we have to make sure that the variable we are binding to our quantifier doesn’t appear in the rest of our sentence. But there’s another catch to this rule: in order to use it, you must be outside of any scope lines on your proof. In my example proof above, I could have used this rule to make another line at the end of the proof, but at no other point in my proof would this rule have been viable.
Once again, we have to make sure that the variable we are binding to our quantifier doesn’t appear in the rest of our sentence. But there’s another catch to this rule: in order to use it, you must be outside of any scope lines on your proof. In my example proof above, I could have used this rule to make another line at the end of the proof, but at no other point in my proof would this rule have been viable.
Universal elimination is much more straightforward:

We don’t have to worry about fresh variables or scope lines or anything else. Because is true for all we can just substitute whatever the hell we want in for . Easy.
4.2.1.11. Identity Introduction and Elimination
Our last (yay!) rule of inference involves the identity relation. Remember that this is a relation between two terms that indicates that they refer to the same entity. The introduction rule is as follows:
 … wait, that’s it? Yep. Without having anything in advance, you can always deduce that any arbitrary term is identical to itself. No baggage required. The elimination rule is a bit more complicated, but really not by much:
… wait, that’s it? Yep. Without having anything in advance, you can always deduce that any arbitrary term is identical to itself. No baggage required. The elimination rule is a bit more complicated, but really not by much:
 If two things are identical, then they can be substituted for each other in any arbitrary sentence ().
If two things are identical, then they can be substituted for each other in any arbitrary sentence ().
4.2.2. Fitch-Rewriting Rules
The following rules allow you to rewrite sentences (or parts of sentences) in Fitch-style derivations. Actually, these rules will pretty much apply to any system of first-order logic. Once again, if you replace the  with a biconditional
with a biconditional  then the resulting sentence is a tautology and will always be valid. Next time, I’ll even teach you how to prove this.
then the resulting sentence is a tautology and will always be valid. Next time, I’ll even teach you how to prove this.
4.2.2.1. Commutativity
As we saw in Part III conjunction, disjunction and biconditionals are all commutative. Thus we have the following rewriting rules:
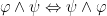

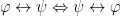
Additionally, the variables in a repeated existential or universal quantification are also commutative. This gives us:


It is important to note, however, that the following are not rewriting rules:


There’s an enormous difference between saying “everyone loves someone” and “someone loves everyone”, which is why the order of terms can only be arranged if they are under the same quantifier.
4.2.2.2. Associativity
Again, as we saw in Part III conjunction, disjunction and biconditionals are associative, meaning that it doesn’t matter what order you evaluate them in:
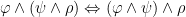
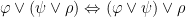
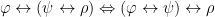
There’s no real difference here between propositional and predicate logics.
4.2.2.3. DeMorgan’s Laws
Also as seen in Part III, we have DeMorgan’s laws which identify the relationship between conjunction, disjunction and negation and allow us to define them in terms of each other.


However, we also have a variation DeMorgan’s Laws which operate on quantifiers:
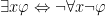

Seriously think about these until they make sense to you. It may help to think of an existential statement as a giant disjunction (ie: “something is round” means “either electrons are round or the Earth is round or squares are round or birds are round…”) and a universal statement as a giant conjunction (ie: “electrons have mass and the Earth has mass and squares have mass and birds have mass”).
4.2.2.4. Double Negation
Double negation is another one that’s straight out of last time:

If isn’t not true, then it must be true. Simple.
4.2.2.5. Definition of
Once again, can be defined in terms of 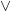 and as follows:
and as follows:
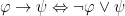
Make sure you understand why this is true as well.
4.2.2.6. Symmetry and Transitivity of Identity
Finally, we have a couple of rules regarding identity. The first is easy enough:

You might ask yourself why this doesn’t fall under commutativity and the answer is a little bit confusing. Commutativity is a rule which applies between sentences. It says that you can swap the order of the sentences on either side of certain connectives. Symmetry is slightly different. It says that you can swap the order of the terms on either side of certain relations. It’s a bit of a technical distinction, but it’s one that’s important to maintain.
Transitivity of identity isn’t really a re-writing rule, but I like to put it here with symmetry because they go well together. Basically it states that if you know that 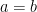 and also that
and also that  then you can also conclude that
then you can also conclude that  . It can be made into a rewriting rule by:
. It can be made into a rewriting rule by:

4.3. Future and Questions
It turns out that there’s actually a lot that needs to be said about first-order logic. As such, I’m going to split it into two (well, two-and-a-half) different entries. Next time I’ll talk about proving validity using Fitch-style systems as well as some strategies for proving things in first-order logic and translations of more complicated sentences. I also want to go over my example derivation and explain step-by-step what’s going on (in fact, I’ll probably do that part first).
In the meantime, here is a handy reference for all of the rules we went over today. See if you can answer the following questions:
- Translate the following sentences into first-order logic:
- All circles are round.
- Some buildings are tall.
- Phil said hello to everyone at the market.
- Joe knows a guy who can get you cheap concert tickets.
- She is her mother’s daughter.
- She got married to someone who owned a farm.
- John is taller than Suzie, but shorter than Pete. Frank is taller than all of them.
- There is at least one apple in that basket.
- There are exactly two apples in that basket.
- There are no more than three apples in that basket.
- Let
 be the sentence “ owns a tractor”. Translate the following sentences:
be the sentence “ owns a tractor”. Translate the following sentences:
- Determine whether the following relations are reflexive, symmetric and/or transitive:
- “is the father of”
- “is related to”
- “is an ancestor of”
- “is the brother of”
- “is the sibling of”
- “is descended from”
- Without using any rewriting rules, use Fitch-style derivations to prove the tautological form of each of the rewriting rules (ie: replace “” with ““.
- Use Fitch-style derivations to prove the following arguments:






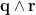

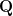
 but that sentence is meaningless unless I also inform you that
but that sentence is meaningless unless I also inform you that  means “
means “ “,
“, 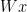 means “
means “ means “
means “ mean “John” and “Amy” respectively.
mean “John” and “Amy” respectively. as being a pair
as being a pair  where
where  is a syntactically defined system of expressions and
is a syntactically defined system of expressions and  is an intended interpretation of those expressions.
is an intended interpretation of those expressions.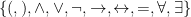 . Our non-logical vocabulary is a bit more complicated in that it needs to potentially address infinitely many variables. There are two ways to do this. The way I like to think of it is having
. Our non-logical vocabulary is a bit more complicated in that it needs to potentially address infinitely many variables. There are two ways to do this. The way I like to think of it is having  which gives you an infinite set containing all of your variables
which gives you an infinite set containing all of your variables 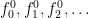 , all of your
, all of your  -place predicates
-place predicates  and all of your
and all of your  -place functions
-place functions 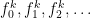 . But, of course, this results in an infinite alphabet of symbols. The book chooses to accomplish this by having your variables be something like
. But, of course, this results in an infinite alphabet of symbols. The book chooses to accomplish this by having your variables be something like  which operates on a finite alphabet (
which operates on a finite alphabet ( ). In either case, we will typically just denote variables as
). In either case, we will typically just denote variables as 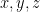 , predicates as
, predicates as  , functions as
, functions as 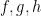 and so on. As stated in the previous section, we don’t always need to use perfect rigour but it’s important to understand how it would be accomplished. The union of the logical and non-logical vocabularies form the language’s alphabet. To see how first-order logic determines its wffs, see
and so on. As stated in the previous section, we don’t always need to use perfect rigour but it’s important to understand how it would be accomplished. The union of the logical and non-logical vocabularies form the language’s alphabet. To see how first-order logic determines its wffs, see  to Socrates and Plato respectively, and the meaning of the predicate
to Socrates and Plato respectively, and the meaning of the predicate  and
and  . Finally,
. Finally,  is true iff
is true iff  is true. This can be tedious but straightforward. Again, however, it is important that this process be an effectively decidable one.
is true. This can be tedious but straightforward. Again, however, it is important that this process be an effectively decidable one. (where
(where 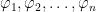 to a conclusion
to a conclusion  is enumerable if its members can – at least in principle – be listed off in some order (a zero-th, first, second) with every member appearing on the list; repetitions are allowed, and the list may be infinite.
is enumerable if its members can – at least in principle – be listed off in some order (a zero-th, first, second) with every member appearing on the list; repetitions are allowed, and the list may be infinite.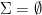 (where
(where  denotes the empty set containing no elements) then trivially all elements of
denotes the empty set containing no elements) then trivially all elements of  is an enumeration of the finite set
is an enumeration of the finite set 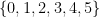 . Similarly,
. Similarly,  also enumerates
also enumerates 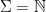 (where
(where  denotes the infinite set containing all natural numbers):
denotes the infinite set containing all natural numbers):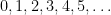


 position. In 2.
position. In 2. 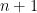 entries down the list if
entries down the list if  entries down if
entries down if 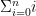 entries into the list. Note that to make the math easier, we start our counting at zero: thus, the left-most element listed is the “zero-th”, the next is the first, the next is the second and so on. Now 2. and 3. are contrived examples but the point they make is that each
entries into the list. Note that to make the math easier, we start our counting at zero: thus, the left-most element listed is the “zero-th”, the next is the first, the next is the second and so on. Now 2. and 3. are contrived examples but the point they make is that each 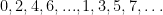


 (so that
(so that  ). We say that such a function enumerates
). We say that such a function enumerates  of infinite binary strings (ie: the set containing strings like
of infinite binary strings (ie: the set containing strings like  ). Obviously
). Obviously  does exist. Then, for example,
does exist. Then, for example, 
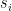 aren’t important (as we will see) so this example will abstract to the general case. What we are going to do now is construct a new string,
aren’t important (as we will see) so this example will abstract to the general case. What we are going to do now is construct a new string,  , such that
, such that 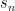 and swap it. Thus, given our example enumeration above, the first 5 characters of
and swap it. Thus, given our example enumeration above, the first 5 characters of  which we get by just this method (for convenience, the
which we get by just this method (for convenience, the 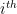 position. As such,
position. As such,  can be thought of as representing a real binary decimal number
can be thought of as representing a real binary decimal number  (ie:
(ie:  would represent
would represent  and
and  would represent
would represent  . Thus we know that the real numbers in the interval
. Thus we know that the real numbers in the interval ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) are not enumerable (and so neither is the set of all real numbers
are not enumerable (and so neither is the set of all real numbers 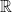 ).
). to be the set
to be the set  , where a number
, where a number  iff
iff  and
and 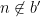 iff
iff 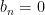 . So for example, if
. So for example, if  then
then  . Thus, the set of sets of natural numbers (denoted
. Thus, the set of sets of natural numbers (denoted  ) is also not enumerable.
) is also not enumerable. which takes a numerical property
which takes a numerical property 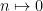 if
if  holds and
holds and  if
if  holds. (This may seem backwards, since
holds. (This may seem backwards, since  and
and  denotes
denotes  , however we will see the reasons for this in due course.) If we consider an element
, however we will see the reasons for this in due course.) If we consider an element 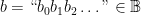 to describe a characteristic function
to describe a characteristic function  by
by  , then we can observe that the set of all characteristic functions is similarly non-enumerable.
, then we can observe that the set of all characteristic functions is similarly non-enumerable.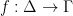 is a rule
is a rule 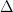 and turns it into something from its co-domain
and turns it into something from its co-domain  . We will be dealing exclusively with total functions, which means that
. We will be dealing exclusively with total functions, which means that  . In other words, the range is the set of all possible outputs of
. In other words, the range is the set of all possible outputs of  there is some
there is some  such that
such that 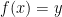 . Equivalently,
. Equivalently,  implies that
implies that  . This property is also called one-to-one because it matches everything with exactly one corresponding value.
. This property is also called one-to-one because it matches everything with exactly one corresponding value. you would probably say no. In either case you have just decided that predicate.
you would probably say no. In either case you have just decided that predicate.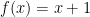 and the argument
and the argument 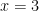 you would compute the value
you would compute the value  . If I give you the function
. If I give you the function  to the argument of the same computer program as above, you would conclude that the result is infinite. In both cases you have just computed that function.
to the argument of the same computer program as above, you would conclude that the result is infinite. In both cases you have just computed that function. -calculus,
-calculus,  -calculus, and even modern programming languages) it has turned out that each of these notions were equivalent to a Turing machine, as well as each other. Thus, Alan Turing and Alonzo Church separately came up with what is now called the Church-Turing thesis (although the book only deals with Turing, hence “Turing’s thesis”):
-calculus, and even modern programming languages) it has turned out that each of these notions were equivalent to a Turing machine, as well as each other. Thus, Alan Turing and Alonzo Church separately came up with what is now called the Church-Turing thesis (although the book only deals with Turing, hence “Turing’s thesis”):
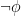 would be provable in
would be provable in  such that neither
such that neither 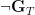 can be derived in
can be derived in  . We will then be able to construct a new Gödel sentence,
. We will then be able to construct a new Gödel sentence,  which will be true but unprovable in
which will be true but unprovable in  . Since
. Since  containing the empty set, followed by the set containing both these sets
containing the empty set, followed by the set containing both these sets  and so on. We get a sequence of the form:
and so on. We get a sequence of the form: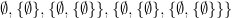
 ), addition is defined as iterated succession, multiplication as iterated addition and all of a sudden you have a theory of arithmetic encompassed in set theory. By Gödel’s First Theorem, then, set theory is also incomplete.
), addition is defined as iterated succession, multiplication as iterated addition and all of a sudden you have a theory of arithmetic encompassed in set theory. By Gödel’s First Theorem, then, set theory is also incomplete. . Thus, any decent theory that proves
. Thus, any decent theory that proves 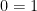 will be inconsistent. Furthermore, an inconsistent theory can prove any proposition, including
will be inconsistent. Furthermore, an inconsistent theory can prove any proposition, including 
 .
.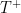 . This rudely defeats what remains of Hilbert’s Programme, as arithmetic isn’t capable of validating itself, let alone the rest of mathematics.
. This rudely defeats what remains of Hilbert’s Programme, as arithmetic isn’t capable of validating itself, let alone the rest of mathematics.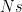
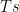



















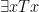


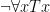

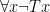





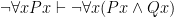

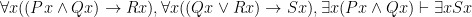
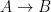



 where what we’ve done is taken the conjunction of the argument’s premises and then stated that they imply the argument’s conclusion. Let’s examine the truth table for this sentence:
where what we’ve done is taken the conjunction of the argument’s premises and then stated that they imply the argument’s conclusion. Let’s examine the truth table for this sentence: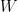
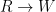
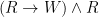
 and examine the resulting truth table.
and examine the resulting truth table.

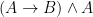
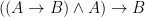

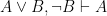
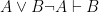
 E) is a rule that states that if a conjunction is true, then so are its conjuncts. It also technically has two forms:
E) is a rule that states that if a conjunction is true, then so are its conjuncts. It also technically has two forms:
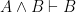


 business come from?” I hear you asking. Well if all we have to work from in an “Or” Elimination (
business come from?” I hear you asking. Well if all we have to work from in an “Or” Elimination (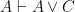




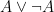 , since no matter what, exactly one of those will always be true (making the whole thing true). Other ones include
, since no matter what, exactly one of those will always be true (making the whole thing true). Other ones include  or many more, which we’ll see below. But the neat thing about tautologies is that they can be inferred from nothing:
or many more, which we’ll see below. But the neat thing about tautologies is that they can be inferred from nothing:
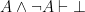

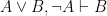 (DS)
(DS) tells us that addition is commutative, since it doesn’t matter whether the
tells us that addition is commutative, since it doesn’t matter whether the  or the
or the 

 first, or whether we add
first, or whether we add  .
.



 and
and  .
. and
and 


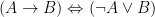


 is equivalent to
is equivalent to 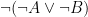
 is equivalent to
is equivalent to 
 ). So for example, we may represent the sentence “It is raining.” with the variable
). So for example, we may represent the sentence “It is raining.” with the variable  or
or  . Under no circumstance will we be dealing with arguments that will use more than 26 clauses, however, if a hypothetical logician were ever to need so many variables, he or she can simply add subscripts to the letters (
. Under no circumstance will we be dealing with arguments that will use more than 26 clauses, however, if a hypothetical logician were ever to need so many variables, he or she can simply add subscripts to the letters ( ).
). possible combinations of truth values, which means
possible combinations of truth values, which means  or
or  . In this example,
. In this example,  or
or 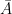 or
or  . We will be using the notation
. We will be using the notation 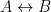 and read “
and read “
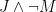 .
.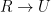 . However a sentence such as “I went to the grocery store, then I bought some milk.” is a different creature. In this case, we are not saying that milk will be bought if I go to the grocery store, but rather I did go there, and then I bought the milk. Thus, such a sentence would be translated as
. However a sentence such as “I went to the grocery store, then I bought some milk.” is a different creature. In this case, we are not saying that milk will be bought if I go to the grocery store, but rather I did go there, and then I bought the milk. Thus, such a sentence would be translated as  . This can be tricky, but a careful analysis of the meaning of the natural English sentence should be enough to determine which situation to apply.
. This can be tricky, but a careful analysis of the meaning of the natural English sentence should be enough to determine which situation to apply. . And this makes sense. If
. And this makes sense. If  were true, then I must be either taking one of the two options. But if I am doing neither, then the opposite of this sentence will be simply its negation. Later we will see that this sentence is actually equivalent to another version:
were true, then I must be either taking one of the two options. But if I am doing neither, then the opposite of this sentence will be simply its negation. Later we will see that this sentence is actually equivalent to another version:  .
. . But why is this? Well the simplest thing to do is to make a truth table the two versions of the sentence:
. But why is this? Well the simplest thing to do is to make a truth table the two versions of the sentence: . This may look complicated, but if you stare at it closely enough, you begin to see how it works: in the first part, we are using our original statement that either John was born on a Tuesday or a Friday; but in the second part we are clarifying that it is not the case that both took place.
. This may look complicated, but if you stare at it closely enough, you begin to see how it works: in the first part, we are using our original statement that either John was born on a Tuesday or a Friday; but in the second part we are clarifying that it is not the case that both took place.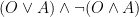 . You can get soup, or you can get salad; but you’re not able to get both soup and salad.
. You can get soup, or you can get salad; but you’re not able to get both soup and salad.

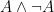



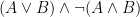 can also be translated as
can also be translated as 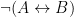 .
.